Please refer to AWS documentation for any unfamiliar all-caps acronyms used throughout this blog post.
I recently completed a work project using Apache Flink (motivated by the need for a streaming application and having to choose between the two offerings from Amazon Kinesis Data Analytics: some sort of proprietary SQL-syntax offering or Flink). This same application was originally written via the SQL approach. It consisted of 10 lines of SQL which allowed it to consume data from a Kinesis stream, aggregate like events based on incoming event timestamp, and output the results to a Kinesis Firehose stream.
The SQL application mostly performed well, but it ran into problems when processing certain large inputs. The traditional guidance when it comes to large/unbounded pieces of data such as these is to store them somewhere and process only references to the stored data. For reasons not germane to this post, we opted against that approach and looked for a way to process the values within the stream processing application itself.
With seemingly no solution to the large value issue within the SQL application approach, we investigated using Apache Flink. Some immediate questions I had were (each discussed in turn below):
- What are its throughput limits?
- What kind of delivery guarantees could we get from Flink with our choice of data source and sink?
- What are the consequences of running Flink within Kinesis Data Analytics?
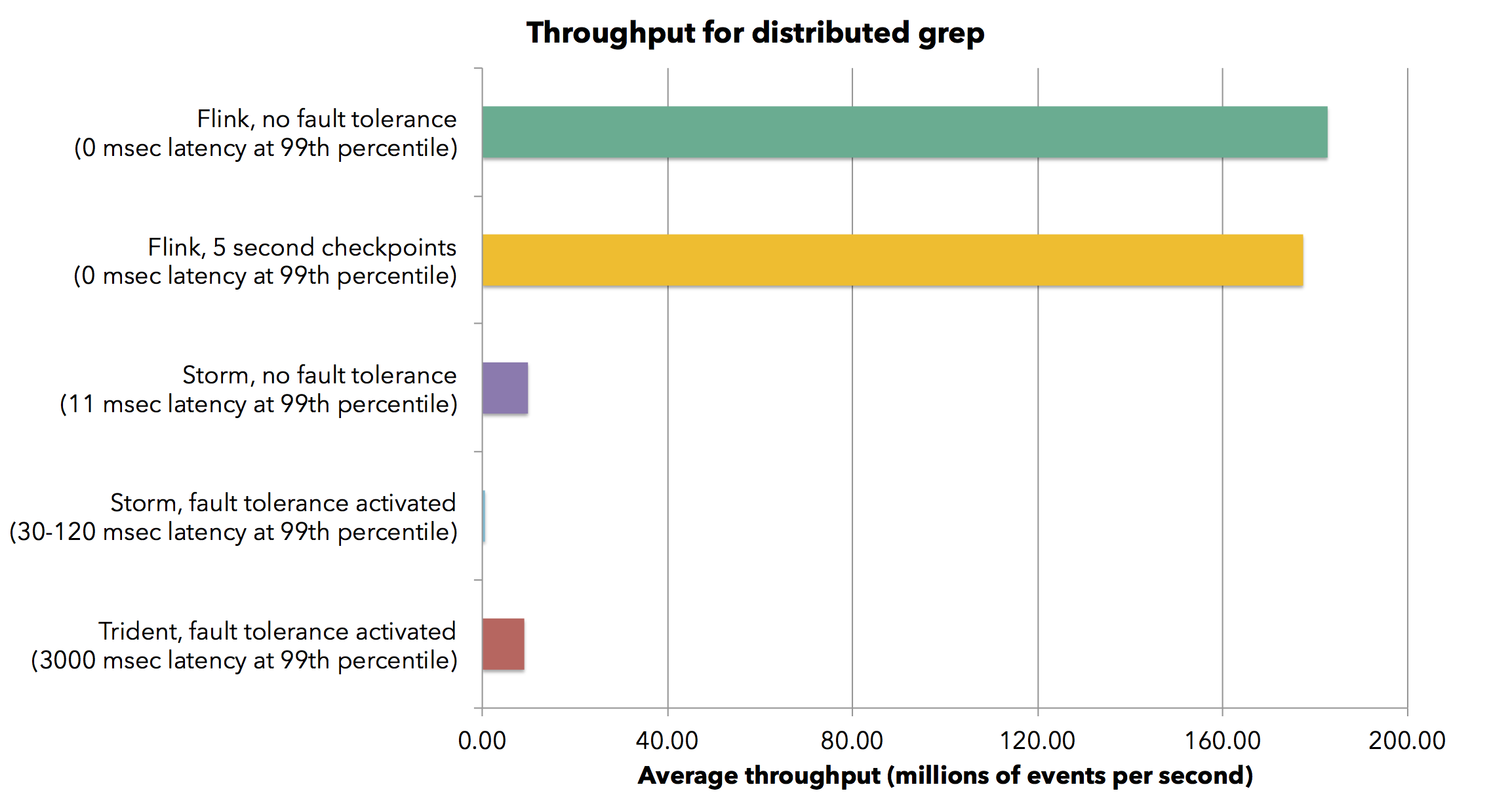
Our application would need to tolerate a lot of data, about 1GB per minute, but it appeared there was nothing to worry about in terms of scalability on Flink's end.
Flink provides exactly once processing guarantees, so it remains to the data sources and sinks (in Flink parlance) to fulfill their end of the guarantee. The Flink Kinesis connector fulfills exactly once processing by tracking the positions of each shard iterator when checkpoints are taken. When resuming an application from a checkpointed state, it simply resumes reading from where it left off. Our application's sink is a Kinesis Firehose stream, and this cannot provide the exactly once guarantee out of the box.
In order for sinks to implement exactly once processing, they must guarantee that writes are either idempotent (which in Firehose they are not) or that they are transactional (i.e. writes are not visible until Flink's checkpoints are complete). Transactionality is also absent using a simple Firehose stream.
These guarantees were sufficient for our needs as the risk of duplicate sends to our Firehose sink are low and only occur in the case where the application shuts down unexpectedly or, somewhat relatedly, a checkpoint fails and we must replay records from a previous checkpoint. For critical data which demands exactly once processing under all circumstances, additional engineering would be required around this problem.
Regarding the idiosyncrasies of operating our service in a Kinesis Data Analytics environment, we learned as we went. KDA with Flink is a relatively new feature (released November 2018), and consequently online resources are somewhat sparse. Running in KDA was a mostly painless process, but like many managed options, visibility is limited compared to a self-hosted approach. It is impossible to install stats collections agents such as statsd on KDA, and the richness of the metrics provided by Amazon doesn't quite compare. Cool things like remote debugging a live instance are not an option. Overall, it's probably a small price to pay for offloading the gruntwork of managing your Flink installation and infrastructure.
Lessons painfully learned
There were a long series of roadblocks when implementing the Flink application. A short summary of these follows.Serialization speed must be considered
Kinesis Data Analytics uses RocksDB, a key/value store which enables Flink to durably persist task data rather than rely on in memory data. This buys us many nice features like incremental checkpoints but requires that data is serialized when passed between tasks. The result is a huge amount of serialization that can quickly overwhelm the CPU if it is too slow. The solution in our case was to provide the required type information to Flink in order to not fallbcak to Flink's last resort serialization scheme, Kryo, which is much slower than the alternatives. This is explained in this article and shown in the chart below.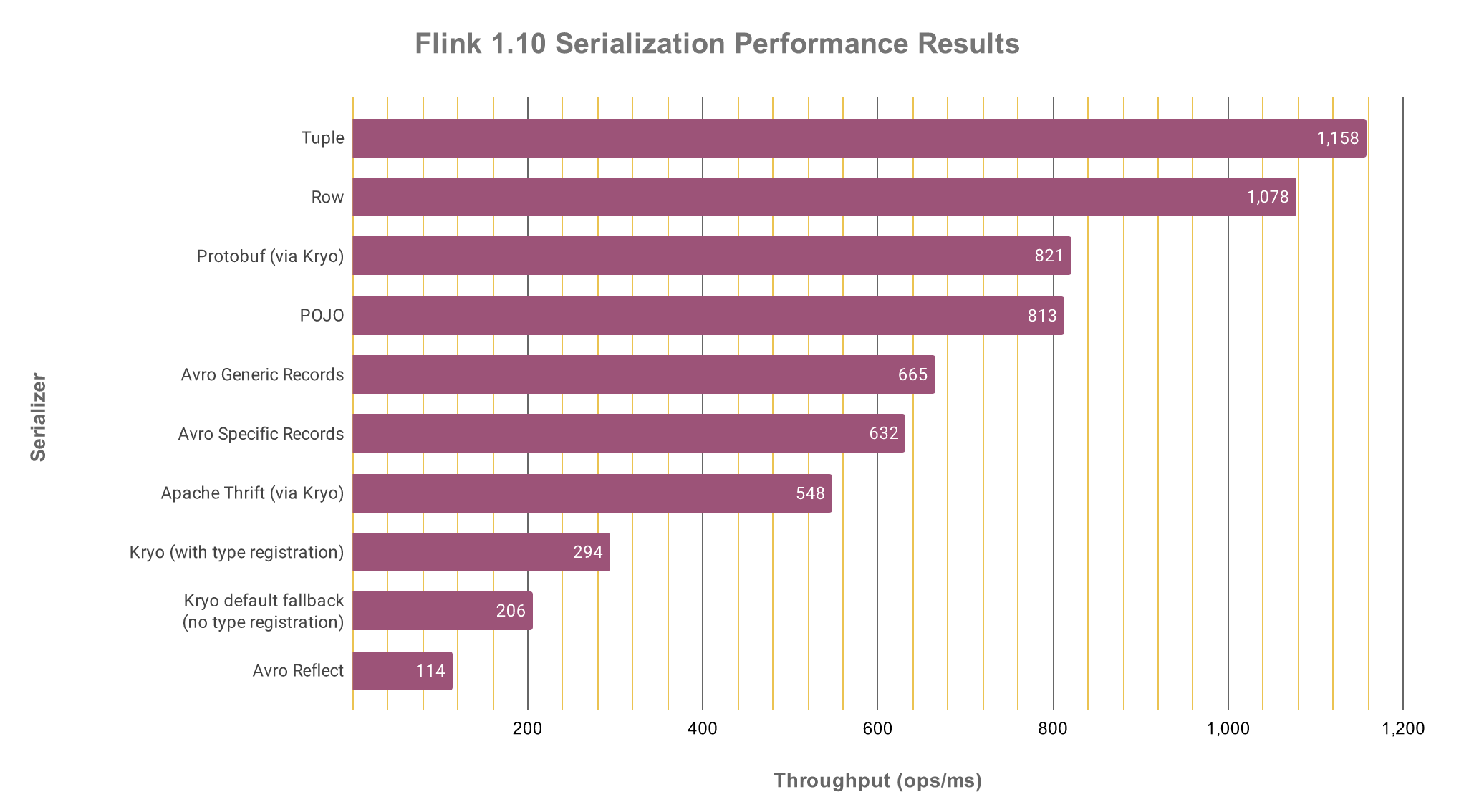 As noted in the article, the serialization penalty for falling back from POJO to Kryo
serialization is about a 75% reduction in performance.
As noted in the article, the serialization penalty for falling back from POJO to Kryo
serialization is about a 75% reduction in performance.
The Kinesis consumer must be tuned carefully
We, probably like the majority of Flink/Kinesis users, use the first-party Kinesis Flink connector. Most throughput issues I encountered were solved by tweaking one or another of its many configuration parameters. The ones we had to tune when all was said and done were:- SHARD_IDLE_INTERVAL_MILLIS: configures how long to wait for new records to appear on a given Kinesis shard before giving up and declaring the shard idle
- WATERMARK_SYNC_QUEUE_CAPACITY: configures how many records each shard consumer can enqueue before they are emitted to downstream consumers
- WATERMARK_LOOKAHEAD_MILLIS: configures how far ahead of the current watermark the consumer is allowed to emit records to downstream tasks
- WATERMARK_SYNC_MILLIS: configures how many milliseconds to wait before requesting watermarks from each shard consumer for the purpose of syncing up their watermarks
- SHARD_GETRECORDS_RETRIES: configures how many times we retry getting records before giving up and killing the application
- SHARD_GETITERATOR_RETRIES: same as above but for getting a shard iterator
- SHARD_GETRECORDS_BACKOFF_MAX: configures how long to wait (at most) before retrying a get records request
- SHARD_GETITERATOR_BACKOFF_MAX: same as above but for getting a shard iterator
Aggregation can be slow for certain Flink state
Our initial draft of our application implemented windowing using aggregation. Aggregation allows Flink to reduce window state to an intermediate, aggregated value in order to reduce state size and reduce burst demand on the application when the window closes.Unfortunately, it turns out that Flink's keyed and operator state cannot be accessed within the context of an aggregation function. Thus, the Flink state, which can be updated very quickly and without deserializing the entire serialized aggregator, cannot be accessed and Flink must deserialize and serialize the intermediate state each time it aggregates the window's records. It seems others have also encountered this problem .
There's no way around understanding the Framework
My hope was that constructing a Flink app would be a quick project and I wouldn't get too into the weeds with the inner workings of the Flink framework. This app confirmed what I held true of frameworks: that any non-trivial project will require you to grapple with their low level details. The thought has certainly crossed my mind whether we could have written a stream processing application without all the heavy-dutiness of Flink, but for anyone writing two or more stream processing applications of this sort, I could see the cost-benefit inequality working out in favor of learning Flink, thereby amortizing the cost of learning its characteristics. The appeal of running in a managed environment via Kinesis Data Analytics means hopefully recouping some maintenance cost in the long-run too, another very attractive proposition.To those seeking to learn Flink, I would recommend Stream Processing with Apache Flink. I discovered it much too late, and I would have saved a lot of time had I started with this book before diving into Flink. It covers Flink with a very logical flow that leads to, in my experience, a much better understanding of the topics presented than documentation on the Flink project website.
Comparison to KDA SQL application
As hoped, the KDA app has so far withstood the large input values which tripped up the SQL implementation. This comes at the expense of a wildly larger amount of code.
$sloccount .
SLOC Directory SLOC-by-Language (Sorted)
566 src_main java=566
408 src_test java=408
Totals grouped by language (dominant language first):
java: 974 (100%)
Both the SQL application and Flink support autoscaling on KDA, though they expose different parameters for tuning it. The Flink runtime offers two parameters:
- Parallelism: The total parallelism of the application
- ParallelismPerKPU: The max # of tasks which can be scheduled on a single KPU
It's too early to weigh in on the comparative operational burden of the two services, but my worst nightmare when running services such as these is magical, unexplainable behavior, and lacking the source code to the SQL runtime makes encountering these sorts of issues seem more likely in the SQL application versus the Flink one.